Sequence Database Setup: EST
Overview
Three EST databases are compiled by the
NCBI (National Center for Biotechnology Information) for Blast searches. They
contain "single-pass" cDNA sequences, or Expressed Sequence Tags, from the EST divisions of
GenBank.
There are currently three EST databases: human, mouse, and others. This document uses the "others" database
as an example. To work with the human or mouse databases, simply substitute the word "human" or
"mouse" for "others". For example, the human
compressed Fasta file is est_human.gz, the db_update.pl keyword is EST_human_from_NCBI, the recommended
Mascot name is EST_human, etc.
Download
ftp://ftp.ncbi.nih.gov/blast/db/FASTA/est_others.gz
for the latest release.
To download updates automatically, the relevant definition block in
db_update.pl is EST_others_from_NCBI.
NOTE est_others.gz has recently grown to be larger than 2 Gb. There is a
bug
in wget that prevents downloading files > 2 Gb on a 32 bit system, so db_update.pl cannot be used for this
particular database on 32 bit platforms (Windows, Linux) until a fix is available.
Taxonomy
Taxonomy for all EST databases is predefined in mascot.dat. For EST_others, choose
"dbEST FASTA using GI2TAXID". The following taxonomy files are required:
ftp://ftp.ncbi.nih.gov/pub/taxonomy/gi_taxid_nucl.dmp.gz
ftp://ftp.ncbi.nih.gov/pub/taxonomy/taxdump.tar.gz
Note that the taxonomy files go into the taxonomy directory, not into the sequence database
directory. Also, some files need to be unpacked (using tar) as well as uncompressed.
Note - Although EST_human and EST_mouse databases are each for a single species, a taxonomy rule
is still required in mascot.dat to indicate which genetic code should be used for translation.
Unigene
The NCBI UniGene
indexes are created by automatically partitioning GenBank sequences into non-redundant sets of
gene-oriented clusters. If UniGene indexes are available locally, results from Mascot searches of
EST databases can be grouped and reported by gene family, rather than by raw EST accession numbers.
To enable UniGene indexes, uncomment the following line, near the top of the
db_update.pl script:
# $local_unigene_directory = "$MASCOT/unigene";
This will cause the required UniGene indexes to be downloaded when the EST databases are next updated.
You will also need to uncomment the relevant lines in the UniGene block of mascot.dat. For example:
# human c:/inetpub/mascot/unigene/human/current/Hs.data
# EST_human human
The links to generate species based UniGene reports will then appear just above the "Repeat Search" buttons
on the Peptide Summary report.
Parse Rules
A typical Fasta title line is:
>gi|16764|emb|Z17609.1|Z17609
ATTS0183 Gif-SeedA+B Arabidopsis thaliana cDNA clone YAP043T 3'
The gi number is the most reliable identifier. Suitable parse rules are:
Accession from Fasta title: ">\(gi|[0-9]*\)"
Description from Fasta title: ">[^ ]* \(.*\)"
If an entry in EST_others represents multiple source database entries, the Fasta title lines are concatenated
together with CTRL+A as the delimiter.
Configuration
For this example, est_others.gz was downloaded to a folder named
C:\Inetpub\MASCOT\sequence\EST_others\current.
The file was decompressed using gzip,
and renamed to EST_others_20020601.fasta.
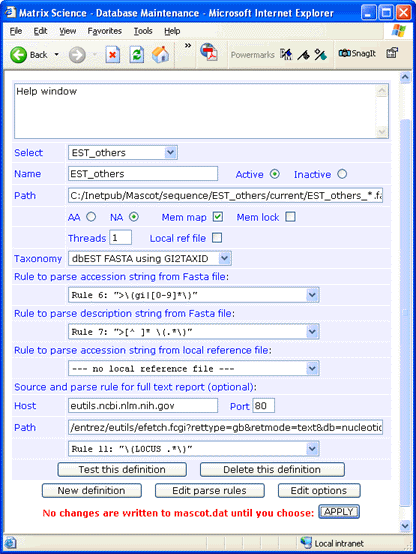
There is no downloadable full text file for EST_others, but full text for individual entries can be retrieved across the web
from the NCBI Entrez server. The syntax
for the Path field is:
/entrez/eutils/efetch.fcgi?rettype=gb&retmode=text&db=nucleotide&tool=mascot&id=#ACCESSION#
If you don't require full text in a Mascot Protein View report, simply leave the Host, Port, and Path fields blank
and choose
--- no full text report ---
in the drop down list.
Always test a new definition before applying the changes to mascot.dat.
|